High Availability
- Stonebranch (Deactivated)
Introduction
High Availability (HA) of Universal Automation Center means that it has been set up to be a redundant system; in addition to the components that are processing work, there are back-up components available to continue processing through hardware or software failure.
This page describes a High Availability environment, how High Availability components recover in the event of such a failure, and what actions, if any, the user must take.
High Availability System
The following illustration is a typical, although simplified, Universal Automation Center system in a High Availability environment.
In this environment, there are:
- Two Universal Controller instances (cluster nodes)
- Two Universal Message Service (OMS) network communications providers in an OMS cluster
- Four Universal Agent (Agent) machines
The components in blue are active and operating. The components in gray are available for operations but currently are inactive (passive).
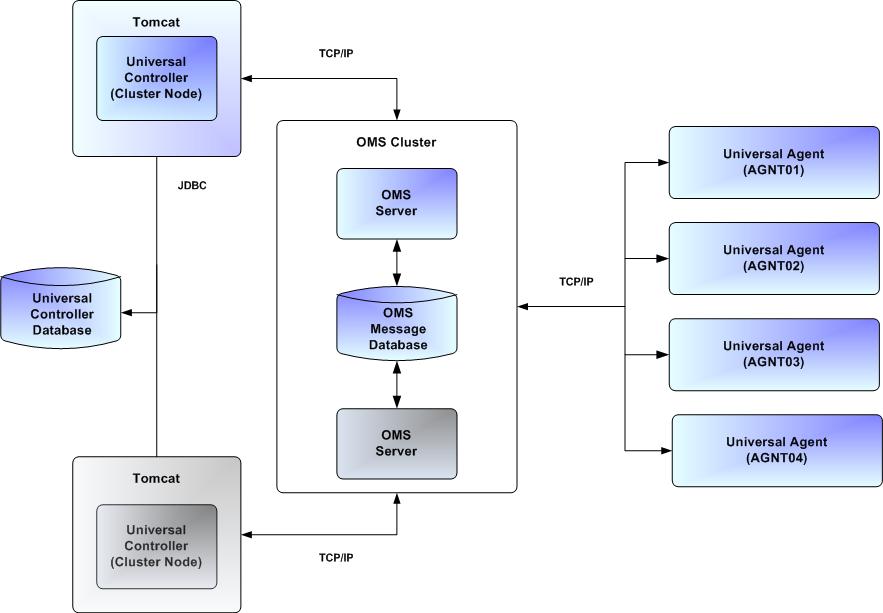
See High Availability Components for a detailed description of how each component type functions in a High Availability environment.
High Availability Components
This section provides detailed information on the cluster nodes and Agents in a High Availability environment.
Cluster Nodes
Each Universal Automation Center installation consists of one or more instances of Universal Controller; each instance is a cluster node. Only one node is required in a Universal Automation Center system; however, in order to run a High Availability configuration, you must run at least two nodes.
At any given time under High Availability, one node operates in Active mode and the remaining nodes operate in Passive mode (see Determining Mode of a Cluster Node at Start-up).
An Active node performs all system processing functions; Passive nodes can perform limited processing functions.
Passive Cluster Node Restrictions
Passive cluster nodes cannot execute any automated or scheduled work.
Also, from a Passive node you cannot:
- Perform a workflow instance insert task operation.
- Perform a bulk import or list import.
- Run the LDAP Refresh server operation.
- Update a task instance.
- Update or delete an enabled trigger.
- Update an enabled Data Backup/Purge.
- Update the Task Execution Limit field in Agent records.
- Update the Task Execution Limit field and Distribution field in Agent Cluster records.
- Update the user Time Zone.
- List Composite Trigger component events.
However, Passive nodes do let you perform a limited number of processing functions, such as:
- Launch tasks.
- Monitor and display data.
- Access the database.
- Generate reports.
Agent
The Agent runs as a Windows service or Linux/Unix daemon. A cluster node sends a request to the Agent to perform a function. The Agent processes the request, gathers data about the operation of the client machine, and sends status and results back to the node. It performs these functions by exchanging messages with the node.
Once an Agent has registered with a node, you can view it by selecting that Agent type from the Agents & Connections navigation pane of the user interface. A list displays showing all the registered Agents of that type. See Agents Overview for more information.
If an Agent fails, Universal Broker restarts it. The Agent then attempts to determine what tasks or functions were in process at the time of failure.
Warm Start Processing is a term used to refer to a process UAG goes through upon startup by which all task instances that were active at the time of the last shutdown (intentional or otherwise) are reviewed and proper action is taken based on state and platform.
- Task instances running on Windows and z/OS platforms are resumed when a Warm Start is attempted.
Task instances running on Unix and Linux platforms are set to IN-DOUBT status when a Warm Start is attempted.
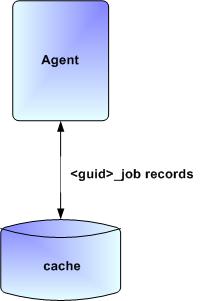
In order to support such a determination, Agent task processing includes the following steps:
Step 1 | Each time the Agent receives a task, it writes to cache a record called |
|---|---|
Step 2 | As the task runs, the Agent updates the |
Step 3 | When the task run completes, the Agent deletes the |
Step 4 | If an Agent is restarted, it looks in the cache for |
As illustrated below, the Agent reads/writes a record to its agent/cache directory for each task instance that it manages.
Universal Message Service (OMS)
Universal Message Service (OMS) sends and receives messages between the cluster nodes and Agents.
OMS consists of an OMS Server and an OMS Administration Utility. The OMS clients - cluster nodes and Agents - establish persistent TCP/IP socket connections with the OMS Server.
OMS provides for reliable message communication by persisting all OMS queued messages to persistent storage. The OMS Server maintains OMS queues in an OMS message database that resides on persistent storage.
See Universal Message Service (OMS) for detailed information on OMS.
How High Availability Works
In a High Availability environment, passive cluster nodes play the role of standby servers to the active (primary) cluster nodes server. All running cluster nodes issue heartbeats and check the mode (status) of other running cluster nodes, both when they start up and continuously during operations. If a cluster node that currently is processing work can no longer do so, one of the other cluster nodes will take over and continue processing.
Each cluster node connects to the same Universal Controller database; however, only the Active cluster node connects to the configured OMS HA cluster. Likewise, each Agent connects to the same OMS HA cluster.
A Universal Controller HA configuration can use a single OMS server, that is not an HA cluster, with the understanding that a single OMS server would introduce a single point of failure. Using an OMS HA cluster is recommended.
See High Availability Configuration for information on how these connections are made.
Cluster Node Mode
The mode (status) of a cluster node indicates whether or not it is the cluster node that currently is processing work:
Active | Cluster node currently is performing all system processing functions. |
|---|---|
Passive | Cluster Node is not connected to OMS but is available to perform all system processing functions, except that it would not be able to exchange data with an Agent. |
Offline | Cluster node is not running or is inoperable and needs to be restarted. |
Note
Cluster nodes in Passive mode can perform limited system processing functions.
High Availability Start-Up
The following steps describe how a High Availability environment starts up:
Step 1 | User starts the Cluster Nodes. |
|---|---|
Step 2 | Each cluster node reads its |
Step 3 | Each cluster node locates and connects to the database and retrieves information about the Universal Automation Center environment. |
Step 4 | Each cluster node connects to an OMS server. |
Step 5 | Each Agent connects to an OMS server. |
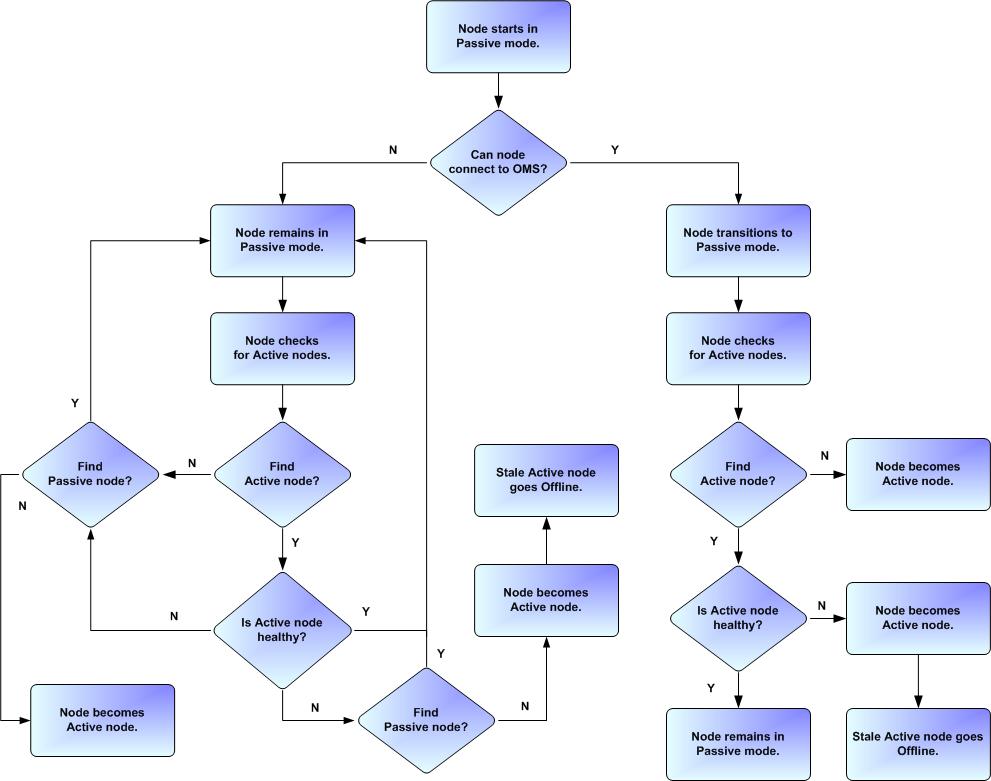
Determining Mode of a Cluster Node at Start-up
A cluster node starts in Passive mode. It then determines if it should remain in Passive mode or switch to Active mode.
The following flow chart describes how a cluster node determines its mode at start-up:
Note
A cluster node is considered "healthy" or "stale" based on its heartbeat timestamp.
Checking the Active Cluster Node During Operations
When all cluster nodes have started, each one continuously monitors the heartbeats of the other running cluster nodes.
If a Passive cluster node determines that the Active cluster node is no longer running, the Passive cluster node automatically takes over as the Active cluster node based upon the same criteria described above.
This determination is made as follows:
Step 1 | The Active cluster node sends a heartbeat by updating a timestamp in the database. The heartbeat interval is 10 (seconds). |
|---|---|
Step 2 | All Passive cluster nodes check the Active cluster node's timestamp to determine if it is current. (This check runs every 60 seconds.) |
Step 3 | If a Passive cluster node determines that the Active cluster node's timestamp is stale, failover occurs: the Passive cluster node changes the mode of the Active cluster node to Offline and takes over as the Active cluster node. If more than one cluster node is operating in Passive mode, the first cluster node eligible to become Active that determines that the Active cluster node is not running becomes the Active cluster node. A stale cluster node is one whose timestamp is older than 5 minutes. |
Checking OMS Connectivity During Operations
When a cluster node is not processing work, it is possible that its OMS Server connection can be silently dropped.
To detect this, a cluster node issues a heartbeat through the OMS server, and back to itself, every 30 seconds if no outgoing activity to the OMS server has occurred. The difference between the time the Controller issues the heartbeat and the time it receives the heartbeat is logged in the uc.log.
What To Do If a Failover Occurs
A Passive cluster node taking over as an Active cluster node is referred to as failover. If failover occurs, the event is invisible unless you are using the Active cluster node in a browser.
If you are using the Active cluster node in a browser and the cluster node fails, you will receive a browser error. In this case, take the following steps to continue working:
Step 1 | Access the new Active cluster node in your browser. To determine which cluster node is now Active, check the Mode column on the Cluster Nodes list in the user interface (see Viewing Cluster Node Status, below). |
|---|---|
Step 2 | If you were adding, deleting, or updating records at the time of the failure, check the record you were working on. Any data you had not yet saved will be lost. |
Note
Running the Pause Cluster Node Server Operation does not induce a failover event. You cannot pause an Active cluster node to create a failover to a Passive cluster node.
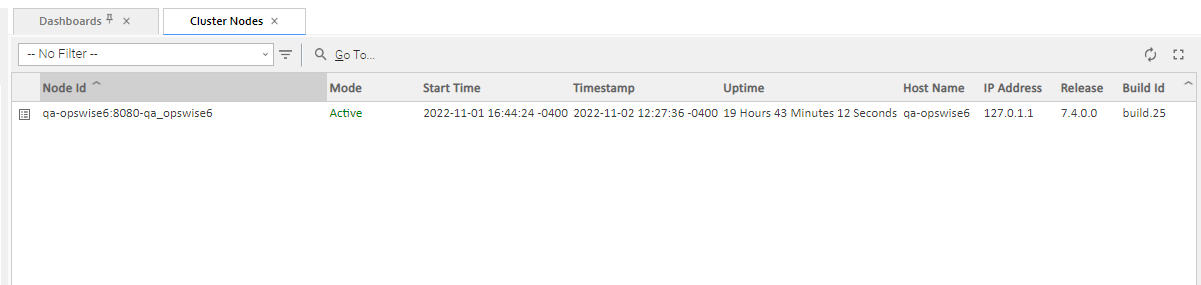
Viewing Cluster Node Status
To view a list of all cluster nodes, from the Agents & Connections navigation pane select System > Cluster Nodes. The Cluster Nodes list identifies all registered cluster nodes. The Mode column on the list identifies the current mode (status) of all cluster nodes.
Note
A cluster node becomes registered the first time it starts. From then on, it always appears in the Cluster Nodes list, regardless of its current mode.
Click any cluster node on the list to display Details for that cluster node below the list. (See Cluster Nodes for a description of the fields in the Details.)
High Availability Configuration
To achieve High Availability for your Universal Automation Center system, you must configure the cluster nodes, OMS, and Agents.
Configuring Cluster Nodes
All cluster nodes in a High Availability environment must point to the same database by making sure the following entries in their uc.properties files are the same.
For example:
Configuring OMS
OMS HA cluster configuration is described in the OMS Reference Guide.
The Universal Controller OMS Server definitions specify an OMS HA cluster as an ordered, comma-separated list of OMS Server addresses, one for each member of the OMS HA cluster.
OMS configuration
Do not define multiple OMS Server records for individual OMS HA cluster members. An OMS HA cluster must be defined as a single OMS Server record with an OMS address list containing each OMS HA cluster member.
As an example, if an OMS HA cluster contains three OMS Servers, oms1.acme.com, oms2.acme.com, and oms3.acme.com, the Universal Controller OMS Server definition would be defined with an OMS Server address value of oms1.acme.com,oms2.acme.com,oms3.acme.com.
Configuring Agents
If you want to configure an Agent to be able to access an OMS HA cluster, you must configure the Universal Automation Center Agent (UAG) OMS_SERVERS configuration option.
Configuring Notifications Based on Component Status
You can configure the Controller to generate Email Notifications or SNMP Notifications based on the mode of your cluster nodes, OMS Servers, and Agents.
Load Balancer
If you are using a load balancer in your High Availability environment, it can utilize the following HTTP requests:
http(s)://serverhost:[Port]/uc/is_active_node.do | If a cluster node is active, this URL returns the status 200 (OK) and a simple one word content of ACTIVE. Note In most cases, you should be able to use the status code for load balancer configuration; however, if you need to scan the response text, you may need to use the following variation of the request: http(s)://serverhost:[Port]/uc/is_active_node.do?api_version=2 |
http(s)://serverhost:[Port]/uc/ops_node_info.do | This URL returns information about a cluster node:
|